The World of Vectors in AI

Why are Vectors a big deal for AI?
Understand what we have been doing so far vs what we can get via AI Vectors as a perfect data type and format.
What are we doing to retrieve the data?
- RDBMS options
- NoSQL and other database options
- Search Indexing Software Options
Our Option-1: When we build any software, we historically used RDBMs to normalize/organize the structured data in two dimensions and retrieve the data with SQL queries. Build (normalize/organize the data) many types of data in two dimensions as tables.
Our Option-2: When we need specific data retrieval and optimizations, we use specific Databases such as NoSQL, time-series, graph databases, etc. Similar to RDBM databases, we normalize/organize the structured data and semi-structured data in two dimensions with some limitations and retrieve the data with better performance vs cost.
Our Option-3: When we need further specific data retrieval and optimizations on unstructured data, we use specific Search Indexing software (Solr, Elastic Search, Open Search, etc). Search Indexing software gives better retrieval capabilities and performance than the above options, where you can apply many dimensions.
What can we get via AI Vectors?
Our Option-4: Leverage Vectors and Embedding Vectors in such a way that we can store trillions of records with 1000s of dimensions and with semantic meanings/relationships.
In today's faster innovation cycles (innovations are faster in young or new startups vs big companies) with a free data world (internet data and other public data sets), Users or Customers demand or create new use cases. For those use cases, Data (Structured and Unstructured) and Dimensions play a big role in Vectors importance.
See below how Data, Dimensions, and Vectors play a role in the AI world.
Data - the key requirement:
Until we know the value of AI for the last few years, we have been focused on limited internal organization data sets.
- So far, we have focused on billions of data records or objects internally at any organization
- But with recent AI-pretrained data, it is all about what 8+ billion people (trillions and trillions of data records, text, images, audio, and videos) are being generated in this world on the internet and on other sources every day.
There is a clear contrast between having focused on just what any organization has done with their internal data vs what they can do with external data generated every day by 8+ billion people.
The new external data with Trillions and trillions of data records, text, images, audio, and videos makes a big difference at the foundation level. That's what you get when you adopt AI models and try to build new AI applications.
Data Dimensions - the key requirement
Once we have the new data (Trillions and trillions of data records, text, images, audio, and videos) in hand via internal and external data sources, we have to look at users' or customers' needs. The typical needs of users or customers are too many and dynamic. When we try to convert those needs or requirements as technical dimensions, we are talking about combinations of billions of dimensions.
Though there were a number of innovations over the last few decades at various storage, databases, computing, and software levels, we still have limitations on the dimensionality of data retrieval.
That means, data dimensions play a big role in satisfying today's users' or customers' needs since the 8+ billion people's needs/demands (in terms of a combination of billions of data dimensions) are much more than what ML can do.
When a software wants to write a document without human intervention, it needs a ton of text and needs to keep the text in proper dimensions and positions.
See below 3072 dimensions importance
Vectors
Since storing petabytes of text and structured data in a traditional database and trying to retrieve via many dimensions is not feasible practically, Vectors came into the picture. They have to be expressed by both magnitude and direction to scale easily.
Vector example: The text "king" is represented as an array [0.212, 0.534, 0.333, 0.751, 0.622, ...]
Embedding
Embedding captures meaning and relationships like:king - man + woman ≈ queen
Embeddings are generated by neural networks that are trained to map input data (like words, sentences, images, or audio) into dense numerical vectors that capture their meaning or features in context via Embedding libraries and Embedding models.
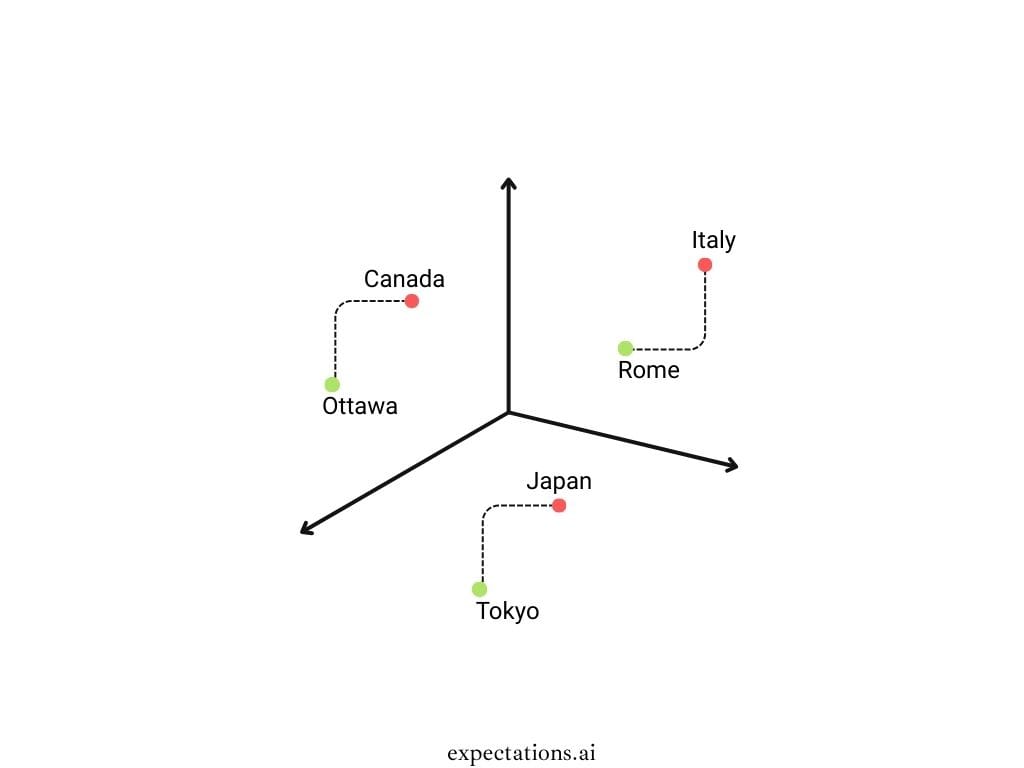
As shown in the above image, the country and capital relationships are preserved based on the vector embeddings, so when the AI Agent wants to generate text, it has all the data with relationships in place appropriately.
With Embedding Vectors, we can store relationships, patterns, and semantic meanings.
The above image shows only 3 dimensions, but we need 1000s of dimensions to satisfy various user/customer needs/requests. See the image below with the 10 dimensions.
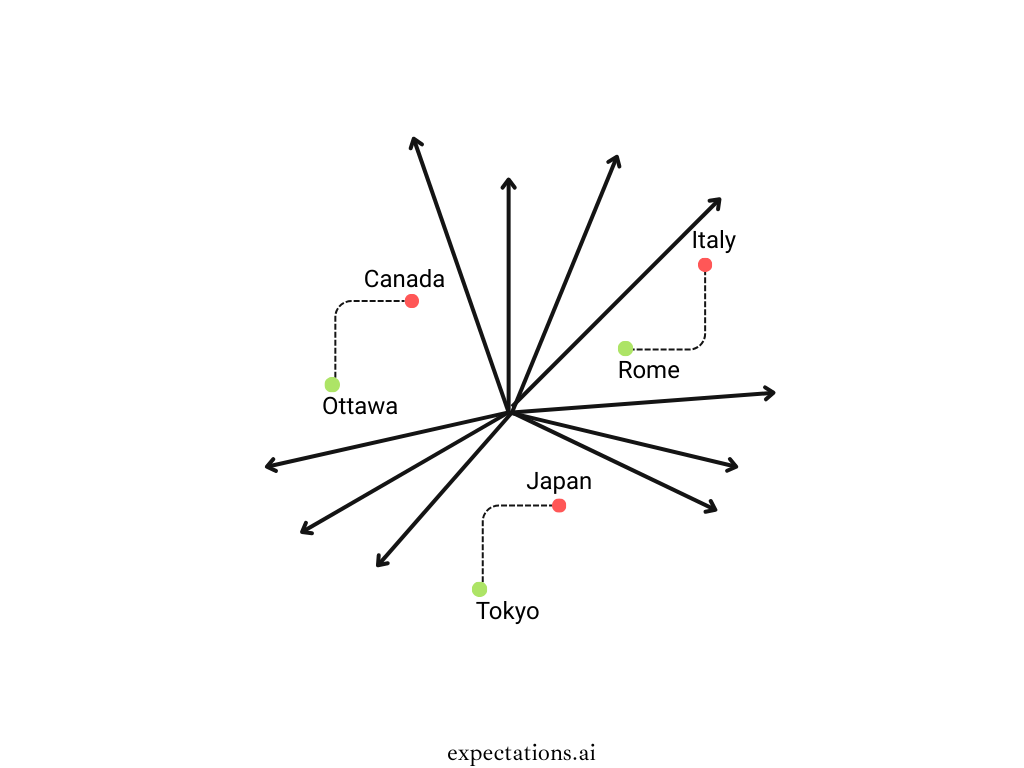
Typical user requests just based on Rome and Italy:
- What is the capital of Italy?
- What is the official capital of Italy?
- Is Rome the capital of Italy?
- What are the two capitals of Italy?
- Why is Rome not the capital of Italy?
- Do you know when Rome became the capital of Italy?
- What is the largest city in Italy?
- What became Italy's capital in 1871?
- When did Rome become Italy's capital?
- What was the capital of Italy before Rome?
I only added 10 related questions from the users, but we can expect 1000s of similar requests. Since we have 1000s of similar requests and content, we need 1000s of dimensions as well. Vectors help us to store the worldwide + organization's text/images/audios/videos in a way that we can keep relationships, semantic meaning, and then retrieve the right text/images/audios/videos.
Word Embedding Examples:
(simplified to 5 dimensions for illustration — real embeddings typically have 100–3072+ dimensions)
| Word | Vector (simplified example, 5 dimensions) |
|---|---|
| king | [0.21, 0.53, 0.33, 0.75, 0.62] |
| queen | [0.20, 0.51, 0.34, 0.72, 0.60] |
| man | [0.18, 0.49, 0.35, 0.70, 0.59] |
| woman | [0.19, 0.48, 0.36, 0.69, 0.61] |
| apple | [0.12, 0.25, 0.45, 0.15, 0.50] |
| fruit | [0.11, 0.27, 0.47, 0.13, 0.52] |
These vectors allow analogies like:
king - man + woman ≈ queen
Sentence Embeddings (from BERT/Sentence-BERT)
| Sentence | Vector (1st 5 values out of 384) |
|---|---|
| "I love pizza." | [0.135, -0.245, 0.089, 0.564, -0.002, ...] |
| "Pizza is my favorite food." | [0.130, -0.240, 0.095, 0.560, -0.004, ...] |
These vectors are very close, showing the model understands their similarity.
Image Embeddings (e.g., CLIP)
| Input Image | Vector (first 5 of 512) |
|---|---|
| 🐶 Dog photo | [0.412, 0.219, -0.311, 0.096, 0.520, ...] |
| 🐕🦺 Another dog photo | [0.408, 0.222, -0.307, 0.101, 0.519, ...] |
| 🚗 Car photo | [0.020, -0.105, 0.244, 0.390, -0.011, ...] |
The dog vectors will be closer together than dog vs car.
Audio Embeddings (e.g., Whisper or Wav2Vec)
| Sound | Vector (first 5 of 1024) |
|---|---|
| Voice saying "hello" | [0.023, -0.119, 0.081, 0.044, 0.331, ...] |
| Voice saying "hi" | [0.025, -0.122, 0.084, 0.048, 0.328, ...] |
Again, similar audio → similar embeddings.
Typical Embedding Models and Use Cases:
| Type | Model | Use Case |
|---|---|---|
| Word | Word2Vec, GloVe | Semantic word similarity, analogy |
| Sentence | BERT, SBERT | Sentence similarity, search |
| Image | CLIP | Vision-language alignment |
| Audio | Whisper, Wav2Vec | Speech recognition, speaker ID |
Vector Databases & AI Models
A list of a few Vector Databases to store organizations' data as Vectors
- ChromaDB
- Milvus
- Pinecone
- Weaviate
- Cloud & Traditional RDBMS databases have vector storage plugins
- Search software such as ElasticSearch, OpenSearch has vector storage plugins
AI Models internally use vectors at all layers
Conclusion
Got the right Data Type and Format as Vectors finally across the organization and across the world data: Store all the structured data and unstructured data including internet data, in the right data type and format (Vectors) so that you can do a lot of automations and magic (automatic content generation, automatic tasks, automatic metrics etc).
Internet-sized data, augmented with the organization's proprietary data, can be converted into Vectors, or Embedding Vectors, to satisfy untapped users' or customers' demands/needs via 1000s of dimensions of queries or unlimited auto-generated text/audio/image/video.
Petabytes of data --> Trillions of vectors --> AI Models --> So many new use cases that satisfy the user or customer needs.
According to some sources, the RefinedWeb data source has more than 5 trillion tokens of textual data. That's just one data source. Therefore, only the imagination is the limit now with the new AI models and technologies.
Check out relevant topics



Check out other internal posts








