AI Tokens
Why Tokens?
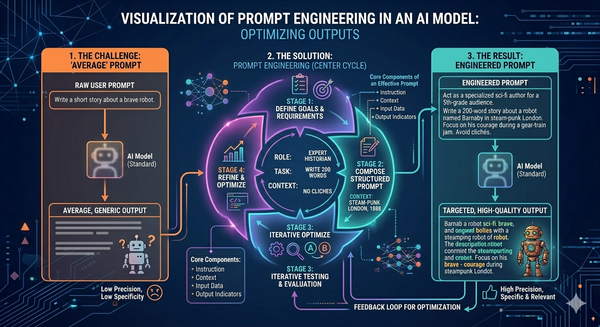
Unlike the traditional way of storing and retrieving data, the AI Model shall build relationships between the text and generate text with the right context, so it requires a special data structure (Vectors) to store it in a unique way (multi-dimensional arrays).
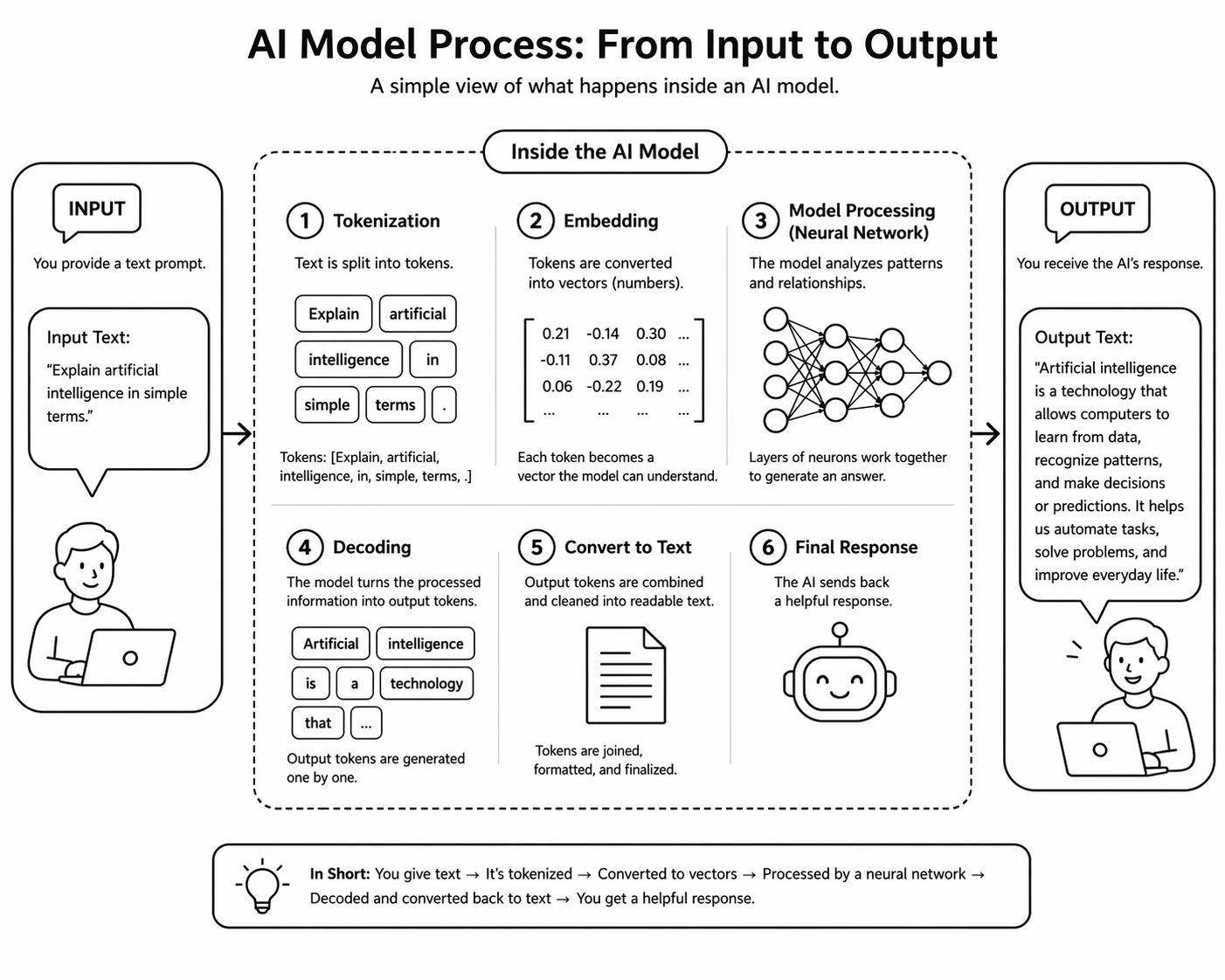
When we have text as input in many use cases, it has to be converted into tokens first and then into vectors. A token is a chunk of text the model processes. A token indeed can be a word, a subword, or a character.
un, believ, able. ,The Process
Step-1: Text → Tokens (Tokenization)
Before anything else, the model uses a tokenizer (often based on Byte Pair Encoding (BPE) or similar methods).
Example:
Why split like this?
- Reduces vocabulary size
- Helps the model understand new/rare words
Step-2: Tokens → Numbers (Token IDs)
Each token is mapped to a unique number:
"believ" → 9821
"able" → 771
Now the sentence becomes:
Step-3: Numbers → Vectors (Embeddings)
Each token ID is converted into a vector (a list of numbers):
These vectors capture meaning:
- “cat” and “dog” → close together
- “cat” and “car” → far apart
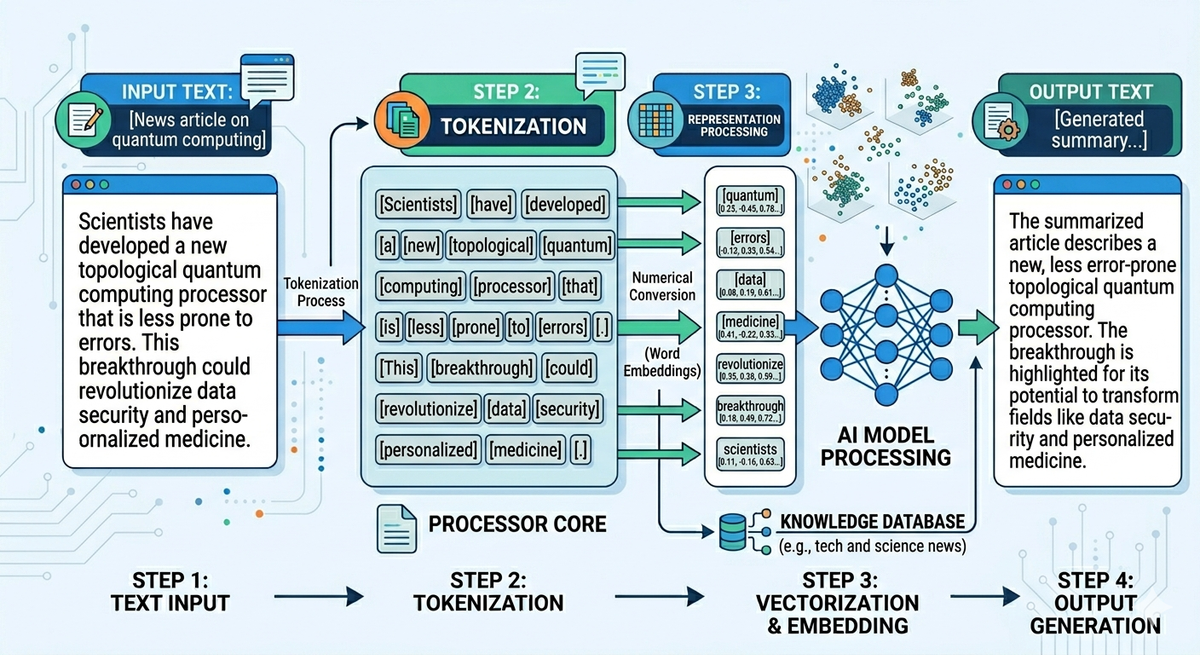
Step-4: Model predicts next token
The model:
- Looks at previous tokens
- Calculates probabilities for the next token
Example
Input: "The house is very"
Output probabilities:
- "big" → 40%
- "small" → 25%
- "beautiful" → 20%
Step-5: Token generation
The model chooses one token (based on probability + randomness settings):
Then repeats:
This loop continues → token by token generation
Entire flow
Speed and Cost
Unlike text, Numbers in a multi-dimensional vector space perform better at less cost and require less infrastructure capacity. Moreover, recent GPU innovations and cloud scale have helped to build and operate AI models without the need for supercomputers.
Check out relevant topics